Информационная безопасность – это состояние информационной системы, в котором угрозы нарушения конфиденциальности, целостности и доступности информации сведены к минимуму.
Конфиденциальность - состояние информации, при котором доступ к ней осуществляют только субъекты, имеющие на него право. Целостность – состояние информации, при котором отсутствует любое ее изменение либо изменение осуществляется только преднамеренно субъектами, имеющими на него право. Доступность– состояние информации, при котором субъекты, имеющие право доступа, могут реализовывать его беспрепятственно.
Правила (3 золотых правила):
Аутентификация - показываем системе идентификатор для получения доступа
Авторизация - у разных пользователей есть разные права и для них даются разные уровни доступа
Аудит - запись, анализ всех действий с данными. Логирование, проверки.
Главная задача: Минимизация угроз.
Полностью защитить невозможно никакую систему. Угрозы: Хакеры, кроты, перехват. Защиты от танков и бпла тоже считается. Направлений много. Мы отвечаем за программные методы, а именно криптографию.
Комплексность—решение в рамках единой концепции двух или более разноплановых задач (целевая комплексность), или использование для решения одной и той же задачи разноплановых инструментальных средств (инструментальная комплексность), или то и другое (всеобщая комплексность). Целевая комплексность означает, что система информационной безопасности должна строиться следующим образом:
защита информации, информационных ресурсов и систем личности, общества и государства от внешних и внутренних угроз;
защита личности, общества и государства от негативного информационного воздействия.
Инструментальная комплексность подразумевает интеграцию всех видов и направлений ИБ для достижения поставленных целей. Структурная комплексность предполагает обеспечение требуемого уровня защиты во всех элементах системы обработки информации. Функциональная комплексность означает, что методы защиты должны быть направлены на все выполняемые функции системы обработки информации. Временная комплексность предполагает непрерывность осуществления мероприятий по защите информации как в процессе непосредственной ее обработки, так и на всех этапах жизненного цикла объекта обработки информации.
Угроза ИБ - потенциально возможное событие, которое может привести к нанесению вреда информационной системе и хранящейся в ней информации.
По природе возникновения угрозы делятся на:
естественные угрозы, вызванные естественными физическими процессами или природными явлениями (наводнениями, землетрясениями, сбоями электропитания и т.п);
искусственными угрозами, вызванными деятельность человека (некомпетентные действия персонала, действия хакеров, злоумышленные действия конкурентов и т.п.).
По степени преднамеренности угрозы различаются как:
угрозы, вызванные ошибками или халатностью персонала, например, неправильное использование информационной системой;
угрозы преднамеренного действия, например, действия злоумышленников.
По местоположению угрозы могут быть:
вне зоны расположения ИС;
в пределах контролируемой зоны ИС; непосредственно в ИС, например, зараженные вирусами программные средства.
По степени вреда, наносимого информационной системе:
несущественное, легко восстановимое нарушение работы ИС;
существенное нарушение работы ИС, требующие серьезных мер по восстановлению нормальной работы;
критическое воздействие на работу ИС, вызвавшее полное крушение системы, или важных компонент ее работы, потеря жизненно важной информации, хранящейся в системе, блокирование каналов связи, требующее длительного времени восстановления и другие угрозы, наносящие существенный вред информационной системе.
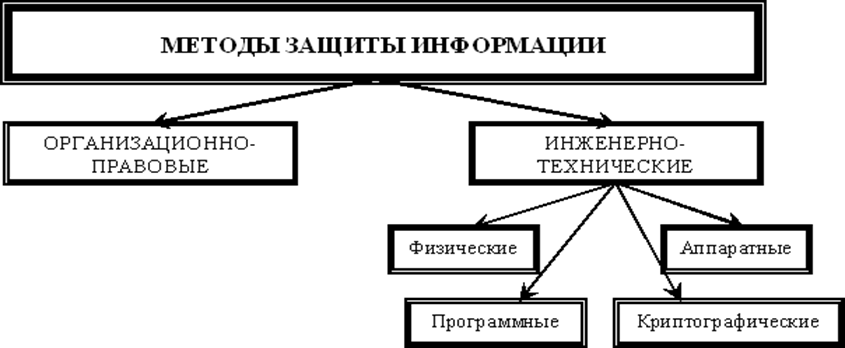
К методам и средствам организационной защиты информации относятся организационно-технические и организационно-правовые мероприятия, проводимые в процессе создания и эксплуатации КС для обеспечения защиты информации.
Инженерно-техническая защита (ИТЗ) – это совокупность специальных органов, технических средств и мероприятий по их использованию в интересах защиты конфиденциальной информации.
По функциональному назначению средства инженерно-технической защиты делятся на следующие группы:
физические средства, включающие различные средства и сооружения, препятствующие физическому проникновению (или доступу) злоумышленников на объекты защиты и к материальным носителям конфиденциальной информации и осуществляющие защиту персонала, материальных средств, финансов и информации от противоправных воздействий;
аппаратные средства – приборы, устройства, приспособления и другие технические решения, используемые в интересах защиты информации. Основная задача аппаратных средств – обеспечение стойкой защиты информации от разглашения, утечки и несанкционированного доступа через технические средства обеспечения производственной деятельности;
программные средства, охватывающие специальные программы, программные комплексы и системы защиты информации в информационных системах различного назначения и средствах обработки (сбор, накопление, хранение, обработка и передача) данных;
криптографические средства – это специальные математические и алгоритмические средства защиты информации, передаваемой по системам и сетям связи, хранимой и обрабатываемой на ЭВМ с использованием разнообразных методов шифрования
Физические средства защиты – это разнообразные устройства, приспособления, конструкции, аппараты, изделия, предназначенные для создания препятствий на пути движения злоумышленников. К физическим средствам относятся механические, электромеханические, электронные, электронно-оптические, радио– и радиотехнические и другие устройства для воспрещения несанкционированного доступа (входа, выхода), проноса (выноса) средств и материалов и других возможных видов преступных действий. Эти средства применяются для решения следующих задач: - охрана территории предприятия и наблюдение за ней; - охрана зданий, внутренних помещений и контроль за ними; - охрана оборудования, продукции, финансов и информации; - осуществление контролируемого доступа в здания и помещения.
К аппаратным средствам защиты информации относятся самые различные по принципу действия, устройству и возможностям технические конструкции, обеспечивающие пресечение разглашения, защиту от утечки и противодействие несанкционированному доступу к источникам конфиденциальной информации. Аппаратные средства защиты информации применяются для решения следующих задач:
проведение специальных исследований технических средств обеспечения производственной деятельности на наличие возможных каналов утечки информации;
выявление каналов утечки информации на разных объектах и в помещениях; локализация каналов утечки информации;
поиск и обнаружение средств промышленного шпионажа;
противодействие несанкционированному доступу к источникам конфиденциальной информации и другим действиям.
Программные методы и средства:
средства собственной защиты, предусмотренные общим программным обеспечением;
средства защиты в составе вычислительной системы;
средства защиты с запросом информации;
средства активной защиты;
средства пассивной защиты и другие.
Направления использования программ для обеспечения безопасности конфиденциальной информации:
защита информации от несанкционированного доступа;
защита информации от копирования;
защита программ от копирования;
защита программ от вирусов;
защита информации от вирусов;
программная защита каналов связи
Программные средства защиты имеют следующие разновидности специальных программ:
идентификации технических средств, файлов и аутентификации пользователей;
регистрации и контроля работы технических средств и пользователей;
обслуживания режимов обработки информации ограниченного пользования;
защиты операционных средств ЭВМ и прикладных программ пользователей;
уничтожения информации в защитные устройства после использования;
сигнализирующих нарушения использования ресурсов;
вспомогательных программ защиты различного назначения.
Криптографические методы защиты информации – это мощное оружие в борьбе за информационную безопасность.
Криптография (от древне-греч. κρυπτος – скрытый и γραϕω – пишу) – наука о методах обеспечения конфиденциальности и аутентичности информации.
Криптография представляет собой совокупность методов преобразования данных, направленных на то, чтобы сделать эти данные бесполезными для злоумышленника. Такие преобразования позволяют решить два главных вопроса, касающихся безопасности информации: - защиту конфиденциальности; - защиту целостности.
Задачи криптографии:
шифрование всего информационного трафика, передающегося через открытые сети;
криптографическая аутентификация, обеспечивает связь разноуровневых объектов;
защита несущего данный трафика средствами имитозащиты (защита от завязания ложных сообщений) и цифровые подписи с целью обеспечения целостности и достоверности предоставляемой информации; шифрование данных, предоставленных в виде файлов или хранящихся в виде базы данных;
контроль целостности программного обеспечения путем применения криптографически стойких контрольных сумм;
применение цифровой подписи для обеспечения юридической значимости документов, применение затемняющей цифровой подписи для обеспечения неотслежимости клиента, платформы системы основанных на электронных деньгах.
Организационное обеспечение компьютерной безопасности включает в себя ряд мероприятий:
организационно-административные;
организационно-технические;
организационно-экономические.
Организационно-административные мероприятия предполагают:
минимизацию утечки информации через персонал (организация мероприятий по подбору и расстановке кадров, создание благоприятного климата в коллективе и т.д.);
организацию специального делопроизводства и документооборота для конфиденциальной информации, устанавливающих порядок подготовки, использования, хранения, уничтожения и учета документированной информации на любых видах носителей;
выделение специальных защищенных помещений для размещения средств вычислительной техники и связи, а также хранения носителей информации;
выделение специальных средств компьютерной техники для обработки конфиденциальной информации;
организацию хранения конфиденциальной информации на промаркированных отчуждаемых носителях в специально отведенных для этой цели местах;
использование в работе сертифицированных технических и программных средств, установленных в аттестованных помещениях;
организацию регламентированного доступа пользователей к работе со средствами компьютерной техники, связи и в хранилище (архив) носителей конфиденциальной информации;
установление запрета на использование открытых каналов связи для передачи конфиденциальной информации;
контроль соблюдения требований по защите конфиденциальной информации.
Система организационных мероприятий, направленных на максимальное предотвращение утечки информации через персонал включает:
оценка у претендентов на вакантные должности при подборе кадров таких личностных качеств, как порядочность, надежность, честность и т.д.;
ограничение круга лиц, допускаемых к конфиденциальной информации;
проверка надежности сотрудников, допускаемых к конфиденциальной информации, письменное оформление допуска; развитие и поддержание у работников компании корпоративного духа, создание внутренней среды, способствующей проявлению у сотрудников чувства принадлежности к своей организации, позитивного отношения человека к организации в целом (лояльность);
проведение инструктажа работников, участвующих в мероприятиях, непосредственно относящихся к одному из возможных каналов утечки информации.
Все лица, принимаемые на работу, проходят инструктаж и знакомятся с памяткой о сохранении служебной или коммерческой тайны. Памятка разрабатывается системой безопасности с учетом специфики организации.
Комплекс организационно-технических мероприятий состоит:
в ограничении доступа посторонних лиц внутрь корпуса оборудования за счет установки различных запорных устройств и средств контроля;
в отключении от ЛВС, Internet тех СКТ, которые не связаны с работой конфиденциальной информацией, либо в организации межсетевых экранов;
в организации передачи такой информации по каналам связи только использованием специальных инженерно-технических средств;
в организации нейтрализации утечки информации по электромагнитным и акустическим каналам;
в организации защиты от наводок на электрические цепи узлов и блоков автоматизированных систем обработки информации;
в проведении иных организационно-технических мероприятий, направленных на обеспечение компьютерной безопасности.
Организационно-технические мероприятия по обеспечению компьютерной безопасности предполагают активное использование инженерно-технических средств защиты.
Проведение организационно-экономических мероприятий по обеспечению компьютерной безопасности предполагает:
стандартизацию методов и средств защиты информации;
сертификацию средств компьютерной техники и их сетей по требованиям информационной безопасности;
страхование информационных рисков, связанных с функционированием компьютерных систем и сетей;
лицензирование деятельности в сфере защиты информации.
Идентификация – процедура распознавания субъекта по его идентификатору. В процессе регистрации субъект предъявляет системе свой идентификатор и она проверяет наличие в своей базе данных.
Аутентификация - процедура проверки подлинности субъекта, позволяющая достоверно убедиться в том, что субъект, предъявивший свой идентификатор, на самом деле является именно тем субъектом, идентификатор которого он использует.
Авторизация – процедура предоставления субъекту определенных прав доступа к ресурсам системы после прохождения им процедуры аутентификации.
Аудит – это процедура записи действий всех пользователей по доступу к защищаемым данным.
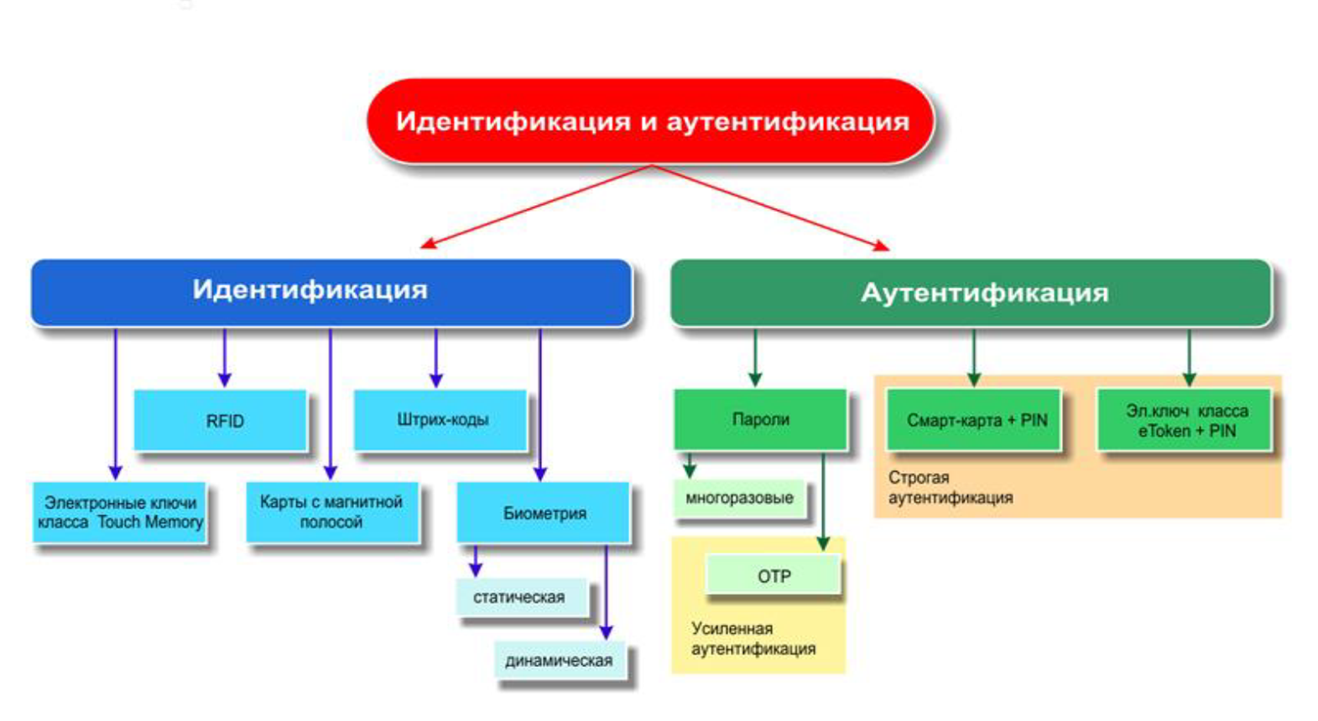

Электронные ключи Touch Memory – одна из разновидностей электронных идентификаторов, широко применяемых во всем мире. По внешнему виду данный тип электронного ключа напоминает плоскую батарейку, толстую пуговицу или таблетку.
Второе название электронных ключей данного семейства – ключи iButton, что означает Information Button (“таблетка” с информацией). Данное название пришло на смену Touch Memory в начале 1997 года. Под этим названием электронные ключи Touch Memory выпускаются по сегодняшний день.

Технология RFID (Radio Frequency Identification — радиочастотная идентификация) – это технология, основанная на использовании радиочастотного электромагнитного излучения. RFID-метка – миниатюрное запоминающее устройство, которое состоит из микрочипа, хранящего информацию, и антенны, с помощью которой метка эти данные передает и получает. В памяти RFID-метки хранится ее собственный уникальный номер и пользовательская информация. Когда метка попадает в зону регистрации, эта информация принимается считывателем, специальным прибором, способным читать и записывать информацию в метках.

NFC (Near Field Communication) — технология беспроводной высокочастотной связи малого радиуса действия (до 10 см), позволяющая осуществлять бесконтактный обмен данными между устройствами, расположенными на небольших расстояниях. Технология NFC базируется на RFID (Radio Frequency IDentification, радиочастотная идентификация)
Три наиболее популярных варианта использования NFC технологии в мобильных телефонах:

Карты с магнитной полосой. В данном типе карты информация заносится на магнитную полосу. Карты с магнитной полосой бывают трёх форматов: ID-1, ID-2, ID-3. Магнитная полоса содержит 3 дорожки, на которые в закодированном виде записывают номер карты, срок ее действия, фамилию держателя карты и тому подобные данные. Объем записанной информации около 100 байт.
Магнитная полоса может быть изготовлена для различных мощностей магнитного поля, и по этому параметру различаютвысококоэрцитивную (HiCo) и низкокоэрцитивную (LoCo). Степень коэрцитивности влияет на устойчивость записанной информации к размагничиванию. Пластиковые карты с магнитной полосой HiCo более надежны и долговечны, так как информация на магнитных полосах HiCo менее подвержена размагничиванию внешними магнитными полями, чем на полосах LoCo.
 Штрих-код — это наносимая в виде штрихов закодированная информация, считываемая при помощи специальных устройств. C
помощью штрихового кода кодируют информацию о некоторых наиболее существенных параметрах объекта.
Штрих-код — это наносимая в виде штрихов закодированная информация, считываемая при помощи специальных устройств. C
помощью штрихового кода кодируют информацию о некоторых наиболее существенных параметрах объекта.
 QR-код (англ. quick response - быстрый отклик) – двумерный штрихкод, разработанный в 1994 году японской фирмой
Denso-Wave. В нём кодируется информация, состоящая из символов (включая кириллицу, цифры и спецсимволы).
Один QR-код может содержать 7089 цифр или 4296 букв.
QR-код (англ. quick response - быстрый отклик) – двумерный штрихкод, разработанный в 1994 году японской фирмой
Denso-Wave. В нём кодируется информация, состоящая из символов (включая кириллицу, цифры и спецсимволы).
Один QR-код может содержать 7089 цифр или 4296 букв.
Биометрия - это идентификация человека по уникальным биологическим признакам. Методы биометрической идентификации делятся на две группы:
Основываются на уникальной физиологической (статической) характеристике человека, данной ему от рождения и неотъемлемой от него.
Основываются на поведенческой (динамической) характеристике человека, построены на особенностях, характерных для подсознательных движений в процессе воспроизведения какого-либо действия.
Биометрические идентификационные системы кодируют в цифровом виде и хранят индивидуальные характеристики, позволяющие практически безошибочно идентифицировать любой индивид.
Двухфакторная аутентификация — это метод идентификации пользователя в каком-либо сервисе при помощи запроса аутентификационных данных двух разных типов, что обеспечивает более эффективную защиту аккаунта.
Многофакторная аутентификация - в процессе которой используются аутентификационные факторы нескольких типов.

Смарт-карты представляют собой пластиковые карты со встроенной микросхемой. В большинстве случаев смарт-карты содержат микропроцессор и операционную систему, контролирующую устройство и доступ к объектам в его памяти. Смарт-карты обладают возможностью проводить криптографические вычисления.
Назначение смарт-карт — одно- и двухфакторная аутентификация пользователей, хранение ключевой информации и проведение криптографических операций в доверенной среде.
Все смарт-карты можно разделить по способу обмена со считывающим устройством на:
Применение смарт-карт:

Электронный идентификатор Рутокен — это компактное USB-устройство, предназначенное для безопасной аутентификации пользователей, защищенного хранения ключей шифрования и ключей электронной подписи, а также цифровых сертификатов и иной информации.

Электронные ключи eToken - персональное средство аутентификации и защищённого хранения данных, аппаратно поддерживающее работу с цифровыми сертификатами и электронной цифровой подписью (ЭЦП). Устройства eToken могут быть в виде USB-ключей, смарт-карт, комбинированных устройств и автономных генераторов одноразовых паролей (OTP)
В настоящее время парольная аутентификация является наиболее распространенной, прежде всего, благодаря своему единственному достоинству – простоте использования.
Однако парольная аутентификация имеет недостатки:
Самая простая идея одноразовых паролей заключается в том, что пользователь получает список паролей P1, Р2,..., Рn. Каждый из паролей действует только на один сеанс входа (Р1 — на первый, Р2 — на второй и т.д.).
Подобная схема имеет свои трудности:
Варианты реализации систем аутентификации по одноразовым паролям:
Принцип работы:
Этот метод реализации технологии одноразовых паролей называется асинхронным, поскольку процесс аутентификации не зависит от истории работы пользователя с сервером и других факторов.
В этом случае алгоритм аутентификации несколько проще:
Этот метод практически идентичен предыдущему.
В настоящее время этот метод получил наиболее широкое распространение.
Этот раздел посвящен фундаментальным принципам криптографии, ее основным строительным блокам и практическим применениям для обеспечения безопасности данных и коммуникаций. Мы рассмотрим различные криптографические примитивы и научимся, как их комбинировать для создания надежных и эффективных протоколов.
Криптография - это наука о методах шифрования и дешифрования данных, обеспечивающих их конфиденциальность, целостность и аутентификацию. Она делится на три основных направления:
Эти три направления представляют собой криптографические примитивы, из которых строятся более сложные протоколы безопасности.
Симметричные и асимметричные методы шифрования имеют свои сильные и слабые стороны, поэтому они часто используются в комбинации:
Комбинированный метод шифрования (также известный как гибридное шифрование) использует сильные стороны обоих подходов. Обычно используется асимметричное шифрование для безопасной передачи симметричного ключа. После того, как симметричный ключ был безопасно передан, он используется для быстрого и эффективного шифрования больших объемов данных.
Представим, что нам нужно отправить сообщение, обеспечив его конфиденциальность и целостность:
MITM (Man-in-the-Middle) атака - это тип кибератаки, при которой злоумышленник перехватывает связь между двумя сторонами и может читать, изменять или добавлять данные в сообщения, не подозревая об этом ни одна из сторон.
Удостоверяющие центры (УЦ) играют ключевую роль в предотвращении MITM-атак. Они выдают цифровые сертификаты, которые удостоверяют подлинность веб-сайта или другого объекта в сети. Когда браузер подключается к веб-сайту, он проверяет сертификат, чтобы убедиться, что сайт является тем, кем он себя выдает.
Этот процесс тесно связан с работой протокола SSL/TLS (Secure Sockets Layer/Transport Layer Security), который обеспечивает безопасное соединение между клиентом (например, браузером) и сервером (например, веб-сайтом). SSL/TLS использует комбинацию симметричного и асимметричного шифрования, цифровые подписи и сертификаты для обеспечения конфиденциальности, целостности и аутентификации данных, передаваемых по сети.
Пусть Z обозначает множество целых чисел. Все рассматриваемые в нашей презентации числа, если не указано особо, принадлежат Z. Опр. Говорят, что два целых числа a и b сравнимы по модулю p, записывается,,если (разность a − b делится на p без остатка). Отношение сравнения по модулю натурального числа обладает следующими свойствами:
Классы эквивалентности, образованные целыми числами по этому отношению, называются вычетами.
Множество классов вычетов по модулю числа натурального n > 0 содержит ровно n элементов, записываемых как
Множество классов вычетов по модулю n образует структуру, являющуюся кольцом. Кольцом K называется непустое множество элементов, на котором определены две арифметические операции сложения + и умножения ·
Свойства:
Обратный по сложению к элемент обозначается через (). Множество элементов, удовлетворяющих только первым трем свойствам, называется группой. Если в группе выполняется свойство коммутативности , то группа называется коммутативной или абелевой. Очевидно, что группа по сложению кольца является абелевой группой. Если модуль является простым числом, то множество ненулевых элементов кольца (обозначаемое через ) образует коммутативную группу по умножению, т.е. существует нейтральный элемент , и для каждого элемента имеется обратный по умножению со свойством .
Элемент называется примитивным элементом или генератором группы, если его порядок равен порядку группы. Не любая группа имеет генератор. Группа, в которой есть генератор, порождается одним элементом и называется циклической.
Теорема. (Малая теорема Ферма) Если число p–простое, то для любого натурального числа , выполняется сравнение , где . Эта теорема является частным случаем теоремы Лагранжа. Действительно, при простом множество ненулевых элементов кольца образует группу по умножению, имеющую элемент. Будем обозначать это множество через
По теореме Лагранжа порядок любого элемента является делителем порядка , откуда
Функция Эйлера мультипликативная арифметическая функция, равная количеству натуральных чисел, меньших n и взаимно простых с ним. Свойства : для всех простых , для простых и натуральных , для любых взаимно простых чисел и
Два целых числа и называются взаимно простыми, если их наибольший общий делитель равен единице, то есть, .
Определение: Пусть — простое нечетное число. Тогда число , такое, что , называется вычетом степени , если .
В обратном случае число a называется невычетом степени . При вычет (невычет) a называется квадратичным, при — кубическим, а при — биквадратичным. При слово квадратичный опускают и называют a просто вычетом (невычетом). Утверждение. В существует ровно квадратичных вычетов, сравнимых с числами: .

Асимптотический закон распределения простых чисел
определяет количество простых чисел от 2 до x
Единица за простое не считается, но и составным не является
Граница Чебышова
Где A=1.05, B= 1.12
Определение: Для любого простого нечетного p и целого a символ Лежандра определяется следующим образом:
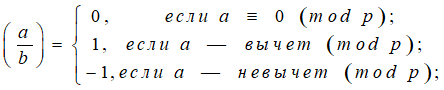
Свойства символа Лежандра:
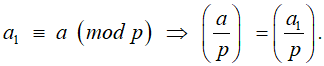
Критерий Эйлера
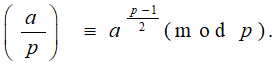
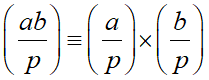
Если НОД(a, p) = 1, то справедливо равенство:

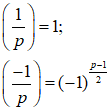
Квадратичный закон взаимности:
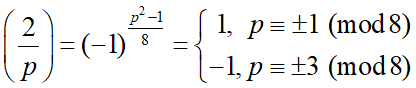
Теорема: Для любых простых нечетных p и q справедливо:
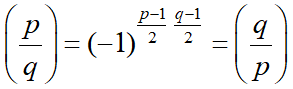
Алгоритм вычисления символа Лежандра. Алгоритм вычисления символа Лежандра является рекурсивным. На практике он неприменим для больших чисел, так как требует разложения числа на простые сомножители.

Алгоритм можно рассматривать как свод правил, руководствуясь которыми, можно вычислить символ Лежандра.

Символ Якоби является обобщением символа Лежандра, а символ Лежандра является частным случаем символа Якоби. Свойства символа Якоби прямо вытекают из соответствующих свойств символа Лежандра Для вычисления символа Якоби в алгоритм вычисления символа Лежандра добавляется нулевой шаг, заключающийся в разложении символа Якоби в произведение символов Лежандра согласно определению.


Очевидно, что любое простое число, не равное 2, является нечетным. Существуют признаки делимости целых чисел на различные простые числа, например, чтобы число в десятичном виде делилось на 3 и 9 достаточно, чтобы сумма его цифр делилась на 3 и 9 соответственно. Чтобы число делилось на 5, достаточно, что его последняя цифра была 0 или 5.
Такие частные признаки делимости можно использовать, если нужно уменьшить множество кандидатов проверки на простоту или отсечь заведомо составные числа. Альтернативным способом получения простых чисел является решето Эратосфена, приписываемое древнегреческому ученому Эратосфену Киренскому, жившему примерно в 276 - 194 г. до н.э.
Для нахождения множества простых до заранее выбранной верхней границы мы сначала выписываем последовательность всех нечетных чисел от 3 до . Затем выбираем первое число в списке, т.е. тройку, и оставляя его в списке, вычеркиваем все кратные 3, начиная с 6. Потом переходим ко второму числу списка (пятерке) и вычеркиваем его кратные, оставив саму пятерку и т.д., пока не дойдем до конца списка. В оставшемся списке будут только простые числа.
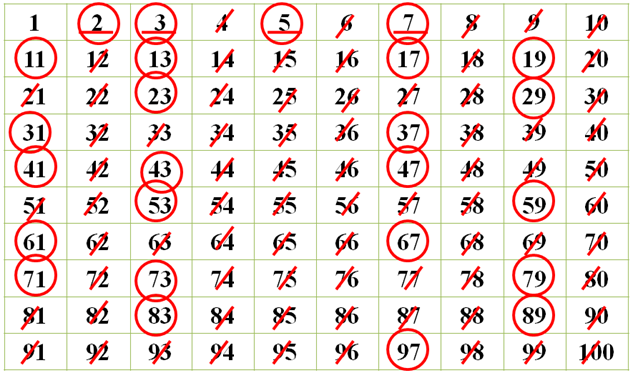
Решето Аткина:
Основная идея алгоритма состоит в использовании неприводимых квадратичных форм (представление чисел в виде ax2 + by2). Предыдущие алгоритмы в основном представляли собой различные модификации решета Эратосфена, где использовалось представление чисел в виде редуцированных форм (как правило, в виде произведения xy).
В упрощённом виде алгоритм может быть представлен следующим образом:
Все числа, равные (по модулю 60) 0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56 или 58, делятся на 2 и поэтому заведомо не простые. Все числа, равные (по модулю 60) 3, 9, 15, 21, 27, 33, 39, 45, 51 или 57, делятся на 3 и тоже не являются простыми. Все числа, равные (по модулю 60) 5, 25, 35 или 55, делятся на 5 и также не простые. Все эти остатки (по модулю 60) игнорируются.
Все числа, равные (по модулю 60) 1, 13, 17, 29, 37, 41, 49 или 53, имеют остаток от деления на 4, равный 1. Эти числа являются простыми тогда и только тогда, когда количество решений уравнения нечётно и само число не кратно никакому квадрату простого числа.
Числа, равные (по модулю 60) 7, 19, 31, или 43, имеют остаток от деления на 6, равный 1. Эти числа являются простыми тогда и только тогда, когда количество решений уравнения нечётно и само число не кратно никакому квадрату простого.
Числа, равные (по модулю 60) 11, 23, 47, или 59, имеют остаток от деления на 12, равный 11. Эти числа являются простыми тогда и только тогда, когда количество решений уравнения (для x > y) нечётно и само число n не кратно никакому квадрату простого.
Тест АКС:
Если существует такое, что и для любого от 1 до выполняется сравнение , то — либо простое число, либо степень простого числа.
Здесь и далее o обозначает показатель числа по модулю , — двоичный логарифм и — функция Эйлера.
Сравнение по двум модулям вида для многочленов означает, что существует такой, что все коэффициенты многочлена , где — кольцо многочленов от над целыми числами.
Метод пробных делений:
Для проверки числа на простоту перебираем числа от 2 до и проверяем делится ли оно на них. Если делится - то число не простое.
Вероятностные тесты, которые входят в класс алгоритмов, определяющих за полиномиальное время, является ли заданное число простым с некоторой вероятностью. При этом за счет времени выполнения алгоритма можно добиться сколь угодно большой вероятности.
По малой теореме Ферма для всех простых чисел и положительных целых чисел , взаимно-простых с , выполняется условие малой теоремы Ферма. Поскольку для большинства составных чисел это условие не выполняется, то мы имеем простейший тест, отделяющий простые числа от большинства составных. Параметр используемый в соотношении малой теоремы Ферма называется базой.
Составное число , для которого условие малой теоремы Ферма истинно, называется псевдопростым по базе . Фактически, псевдопростые числа – это числа, на которых тест Ферма дает ошибку, трактуя составные числа как вероятно простые.
Тест Ферма:
Если — простое число, то оно удовлетворяет сравнению для любого , которое не делится на .
Выполнение сравнения является необходимым, но не достаточным признаком простоты числа. То есть, если найдётся хотя бы одно , для которого , то число — составное; в противном случае ничего сказать нельзя, хотя шансы на то, что число является простым, увеличиваются. Если для составного числа n выполняется сравнение , то число называют псевдопростым по основанию . При проверке числа на простоту тестом Ферма выбирают несколько чисел . Чем больше количество , для которых , тем больше шансы, что число простое. Однако существуют составные числа, для которых сравнение выполняется для всех , взаимно простых с — это числа Кармайкла. Чисел Кармайкла — бесконечное множество, наименьшее число Кармайкла — 561. Тем не менее, тест Ферма довольно эффективен для обнаружения составных чисел.
Тест Соловея-Штрассена:
Алгоритм Соловея — Штрассена параметризуется количеством раундов . В каждом раунде случайным образом выбирается число . Если , то выносится решение, что составное. Иначе проверяется справедливость сравнения . Если оно не выполняется, то выносится решение, что — составное. Если это сравнение выполняется, то является свидетелем простоты числа . Далее выбирается другое случайное и процедура повторяется. После нахождения свидетелей простоты в раундах выносится заключение, что является простым числом с вероятностью .
Тест Люка-Леммера:
Начнем с описания алгоритма. Пусть задано натуральное нечетное число , большее трех. Представим число в виде нечетно. (1) Алгоритм Миллера-Рабина состоит из отдельных итераций, называемых раундами. Каждый раунд либо определяет число , как составное, либо усиливает вероятность того, что является простым числом. Опишем инструкции выполнения одного раунда:
Выбираем случайное целое число в диапазоне от 2 до . Вычисляем
Проверяем условие (2) Если (2) выполнено, то число n вероятно простое, переходим к следующему раунду.
Иначе, вычисляем последовательность , полагая (3) Если ни один из членов этой последовательности не эквивалентен -1 по модулю , тогда утверждаем, что – составное. Иначе, подтверждает – вероятно простое.
Тест Миллера-Рабина работает достаточно быстро и эффективно, однако, как ранее говорили, существуют составные числа, успешно проходящие тест Миллера –Рабина
Определение: Пусть – произвольное натуральное число. Назовем нечетное составное натуральное число строго псевдопростым по базе или , если число успешно проходит один раунд теста Миллера-Рабина с базой . Иначе говоря, выполняется одно из следующих условий: для некоторого , (4) где .
Асимметричная шифрсистема — система шифрования, в которой используются ключи двух видов — открытые ключи и секретные ключи. Открытый ключ применяется в процессе зашифрования и, как правило, является общедоступным. Секретный ключ используется в процессе расшифрованиясообщения и должен храниться в тайне получателем сообщения.
Криптографическая стойкость асимметричной системы определяется трудоемкостью, с которой злоумышленник может вычислить секретный ключ исходя из знания открытого ключа и другой дополнительной информации о шифрсистеме.
Основным преимуществом асимметричной шифрсистемы является то, что абонентам не нужно заранее договариваться об общем секретном ключе.
Основы криптографии с открытыми ключами были выдвинуты Уитфилдом Диффи (Whitfield Diffie) и Мартином Хеллманом (Martin Hellman), и независимо Ральфом Мерклом (Ralph Merkle). Их вкладом в криптографию было убеждение, что ключи можно использовать парами - ключ шифрования и ключ дешифрирования - и что может быть невозможно получить один ключ из другого.
Здесь нашла свое применение математическая теория сложных задач. Оказалось возможным строить такие математические функции, которые «легко» вычисляются, а обращаются «очень трудно»: для этого необходимы нереальные вычислительные ресурсы и время. Однако если для подобной функции известна некоторая дополнительная информация (ее часто называют «лазейкой»), то обратить функцию можно тоже «легко». Такие функции называются односторонними.
До сих пор существование односторонних функций строго не доказано. Но имеется несколько функций-кандидатов, обладающих свойствами односторонних функций. Они используются для построения современных асимметричных шифрсистем.
Необратимые преобразования:
Плюсы:
Могут работать по открытому каналу связи.
Легкий обмен ключами.
Простая реализация.
Минусы:
Обычно ими шифруют подписи или потоковые ключи.
Одним из них является:
Алгоритм Диффи-Хеллмана.
Сервер отправляет пользователю параметры и , а также число
Пользователь на основе полученного сообщения вычисляет и .
Полученное значение отправляется на сервер.
Сервер, получив , вычисляет . Таким образом, сервер и пользователь сгенерировали общий сеансовый ключ .
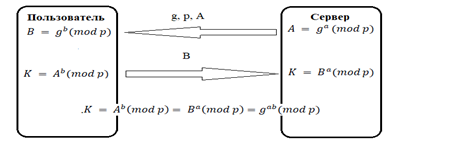
Алгоритм Диффи-Хелмана, обеспечивая конфиденциальность передачи ключа, не может гарантировать того, что он прислан именно тем партнером, который предполагается.
Для решения этой проблемы был предложен протокол STS (station-to-station).
Этот протокол для идентификации отправителя использует технику электронной цифровой подписи. Подпись шифруется общим секретным ключом, после того как он сформирован.
Алгоритм Диффи-Хеллмана.
Сервер отправляет пользователю параметры и , а также число
Пользователь на основе полученного сообщения вычисляет и .
Полученное значение отправляется на сервер.
Сервер, получив , вычисляет . Таким образом, сервер и пользователь сгенерировали общий сеансовый ключ .

Алгоритм Диффи-Хелмана, обеспечивая конфиденциальность передачи ключа, не может гарантировать того, что он прислан именно тем партнером, который предполагается.
Для решения этой проблемы был предложен протокол STS (station-to-station).
Этот протокол для идентификации отправителя использует технику электронной цифровой подписи. Подпись шифруется общим секретным ключом, после того как он сформирован.
Рассмотрим атаку на протокол выработки общего секрета Диффи-Хеллмана между сторонами и . Допустим, криптоаналитик имеет возможность не только перехватывать сообщения, но и подменять их своими, то есть осуществлять активную атаку


Пусть в некоторой конечной мультипликативной абелевой группе задано уравнение . (1)
Решение задачи дискретного логарифмирования состоит в нахождении некоторого целого неотрицательного числа , удовлетворяющего уравнению (1). Если оно разрешимо, у него должно быть хотя бы одно натуральное решение, не превышающее порядок группы. Это сразу даёт грубую оценку сложности алгоритма поиска решений сверху — алгоритм полного перебора нашёл бы решение за число шагов не выше порядка данной группы.
Чаще всего рассматривается случай, когда , то есть группа является циклической, порождённой элементом . В этом случае уравнение всегда имеет решение. В случае же произвольной группы вопрос о разрешимости задачи дискретного логарифмирования, то есть вопрос о существовании решений уравнения (1), требует отдельного рассмотрения.
Итак, алгоритм Диффи-Хелмана, обеспечивая конфиденциальность передачи ключа, не может гарантировать того, что он прислан именно тем партнером, который предполагается.
Для решения этой проблемы был предложен протокол STS (station-to-station).
Этот протокол для идентификации отправителя использует технику электронной цифровой подписи. Подпись шифруется общим секретным ключом, после того как он сформирован.
В криптографии центр сертификации или удостоверяющий центр (англ. Certification authority, CA) — сторона (отдел, организация), чья честность неоспорима, а открытый ключ широко известен. Задача центра сертификации — подтверждать подлинность ключей шифрования с помощью сертификатов электронной подписи.
Технически центр сертификации реализован как компонент глобальной службы каталогов и отвечает за управление криптографическими ключами пользователей. Открытые ключи и другая информация о пользователях хранится удостоверяющими центрами в виде цифровых сертификатов.
Цифровой сертификат — выпущенный удостоверяющим центром электронный или печатный документ, подтверждающий принадлежность владельцу открытого ключа или каких-либо атрибутов.
Сертификат открытого ключа удостоверяет принадлежность открытого ключа некоторому субъекту, например, пользователю. Сертификат открытого ключа содержит имя субъекта, открытый ключ, имя удостоверяющего центра, политику использования соответствующего удостоверяемому открытому ключу закрытого ключа и другие параметры, заверенные подписью удостоверяющего центра.
Сертификат открытого ключа используется для идентификации субъекта и уточнения операций, которые субъекту разрешается совершать с использованием закрытого ключа, соответствующего открытому ключу, удостоверяемому данным сертификатом.

RSA (аббревиатура от фамилий Rivest, Shamir и Adleman)—криптографический алгоритм с открытым ключом, основывающийся на вычислительной сложности задачи факторизации больших целых чисел.
Для шифрования текстовой строки выполним следующие действия:
Для реализации алгоритма RSA требуется использовать алгоритм быстрого возведения в степень по модулю заданного натурального числа. Предположим, что требуется вычислить . Рассмотрим следующий алгоритм:
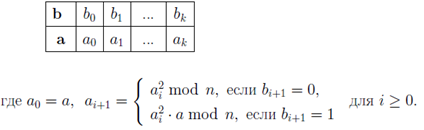
Результат появится в последней ячейке второй строки.
Атака Хастеда, Атака на основе малой экспоненты, Атака Винера.
Факторизацией целого числа называется его разложение в произведение простых сомножителей. Такое разложение, согласно основной теореме арифметики, всегда существует и является единственным (с точностью до порядка следования множителей). Все методы факторизации в зависимости от их производительности можно разбить на две группы: экспоненциальные методы и субэкспоненциальные методы. Все эти методы достаточно трудоемки, поэтому требуют значительных вычислительных ресурсов для чисел большой длины. Однако теоретическое обоснование необходимой сложности таких вычислений или, другими словами, существование высоких нижних оценок не доказано, поэтому вопрос о существовании алгоритма факторизации с полиномиальной сложностью на классическом компьютере для выполнения факторизации является одной из важных открытых проблем современной теории чисел. В то же время факторизация с полиномиальной сложностью возможна на квантовом компьютере с помощью алгоритма Шора. В этой главе мы дадим описание наиболее известных алгоритмов факторизации, имеющих экспоненциальную оценку сходимости.
Не уверен нужно ли расписывать методы... НО!
Пусть – известное целое число, являющееся произведением двух неизвестных простых чисел и , которые требуется найти. Большинство современных методов факторизации основано на идее, предложенной еще Пьером Ферма, заключающейся в поиске пар натуральных чисел и таких, что выполняется соотношение: Алгоритм Ферма может быть описан следующим образом:
Вычислим целую часть от квадратного корня из : .
Для будем вычислять значения ,
до тех пор, пока очередное значение q(x) не окажется равным полному квадрату.
Этот метод был разработан Джоном Поллардом в 1975 г. Пусть – число, которое следует разложить. -метод Полларда работает следующим образом:
Пусть факторизуемое число, а – его простой делитель. Согласно малой теореме Ферма, для любого , выполняется условие . Это же сравнение выполнится, если вместо степени взять произвольное натуральное число кратное , т.к. если , то . Последнее условие эквивалентно для некоторого целого . Отсюда, если является делителем числа , тогда является делителем наибольшего общего делителя и совпадет с , если . Пусть
. Идея –метод Полларда состоит в чтобы выбрать в виде произведения как можно большего числа простых сомножителей или их степеней так, чтобы делилось на каждый сомножитель , входящий в разложение выше. Тогда, даст искомый делитель. Алгоритм состоит из двух стадий:
Если в результате первого этапа алгоритм не выдает требуемого делителя, то можно либо увеличить границу , либо начать вторую стадию работы алгоритма. Вторая стадия алгоритма предполагает, что существует только один простой множитель числа , значение которого больше границы . Выберем новую границу , например, . Обозначим через число , вычисленное на первой стадии работы алгоритма. Выпишем последовательность всех простых чисел на интервале . Для построения этого множества можно воспользоваться решетом Эратосфена, либо решетом Аткина.
Поскольку наличие в последовательности нескольких составных чисел не испортит работы алгоритма, можно выполнить только частичное просеивание, отсеяв числа, кратные небольшим простым числам. Это ускорит общую работу алгоритма.
Если искомый множитель равен , то для нахождения делителя , необходимо вычислить , и найти . Поскольку, значение неизвестно, мы должны выполнить последние две операции с каждым числом из интервала . Поллард предложил следующий вариант организации этой процедуры. Обозначим через разность между соседними простыми числами . Возможные значения, принимаемые , лежат в небольшом множестве . Можно заранее вычислить все значения для и сохранить полученные числа в массиве. Вторая стадия алгоритма выполняется следующим образом:
Поскольку все значения заранее вычислены, то для вычисления очередного значения достаточно одной операции умножения и вычисления остатка по модулю . Поэтому вторая стадия алгоритма Полларда выполняется очень быстро.
Определение: Последовательностью Люка (Lucas) назовем реккурентную последовательность un , определяемую соотношениями: , (2.26) где , – фиксированные целые числа. –метод Вильямса (Williams) похож на –метод Полларда и основан на предположении гладкости числа . Пусть –простой делитель факторизуемого числа , и выполнено разложение
Обозначим через . По-прежнему будем называть натуральное число –степенно-гладким, если наибольшая степень сомножителя в разложении на простые множители, не превышает . Таким образом, определенное выше число является наименьшим числом, для которого является –степенно-гладким. Отметим, что поскольку не известно, то и так же не известно. Алгоритм Уильямса заключается в следующем:
Доказано, что если взаимно просто с и , то свойства последовательности Люка обеспечивают нахождение нетривиального делителя числа .
Факторизацией целого числа называется его разложение в произведение простых сомножителей. Такое разложение, согласно основной теореме арифметики, всегда существует и является единственным (с точностью до порядка следования множителей). Все методы факторизации в зависимости от их производительности можно разбить на две группы: экспоненциальные методы и субэкспоненциальные методы. Все эти методы достаточно трудоемки, поэтому требуют значительных вычислительных ресурсов для чисел большой длины. Однако теоретическое обоснование необходимой сложности таких вычислений или, другими словами, существование высоких нижних оценок не доказано, поэтому вопрос о существовании алгоритма факторизации с полиномиальной сложностью на классическом компьютере для выполнения факторизации является одной из важных открытых проблем современной теории чисел. В то же время факторизация с полиномиальной сложностью возможна на квантовом компьютере с помощью алгоритма Шора.
Алгоритмы субэкспоненциальной сложности: Метод Диксона, квадратичного решета, решета числового поля, алгоритмы факторизации на основе эллиптических кривых.
Метод факторизации квадратичным решетом — это алгоритм, используемый для разложения больших целых чисел на простые множители. Он является одним из самых эффективных методов факторизации для чисел среднего размера и основывается на идее нахождения гладких чисел, которые можно разложить на множители из небольшого набора простых чисел. Вот основные шаги алгоритма:
Выбор параметров:
Выберите базу B, состоящую из небольших простых чисел:
Определите границу гладкости , которая зависит от размера числа , которое вы хотите факторизовать.
Поиск гладких чисел:
Создание системы уравнений:
Решение системы уравнений:
Поиск факторов:
Проверка и вывод результатов:
Этот метод эффективен для чисел среднего размера, но для очень больших чисел может потребоваться более сложный алгоритм, такой как общее числовое решето.
Задача дискретного логарифмирования - ешё одна (наряду с факторизацией) задача, на сложности которой основана стойкость ряда криптосистем, самые известные из которых - схема распределения ключей Диффи-Хеллмана и криптосистема Эль-Гамаля. Состояние дел относительно её сложности такое же, как и для задачи факторизации - на сегодня не найдено полиномиальных алгоритмов её решения, но и не доказано, что их не существует. Пусть - конечная циклическом группа с порождающим элементом , и - произвольный элемент из . Тогда существует единственное целое значение , такое, что Это значение называется дискретным логарифмом по основанию , обозначается .


Работают быстро, сложно передавать и хранить ключи чтобы их не достали. Это делается комбинированием с асимметричными методами. Делятся на Блочные и Поточные шифры.




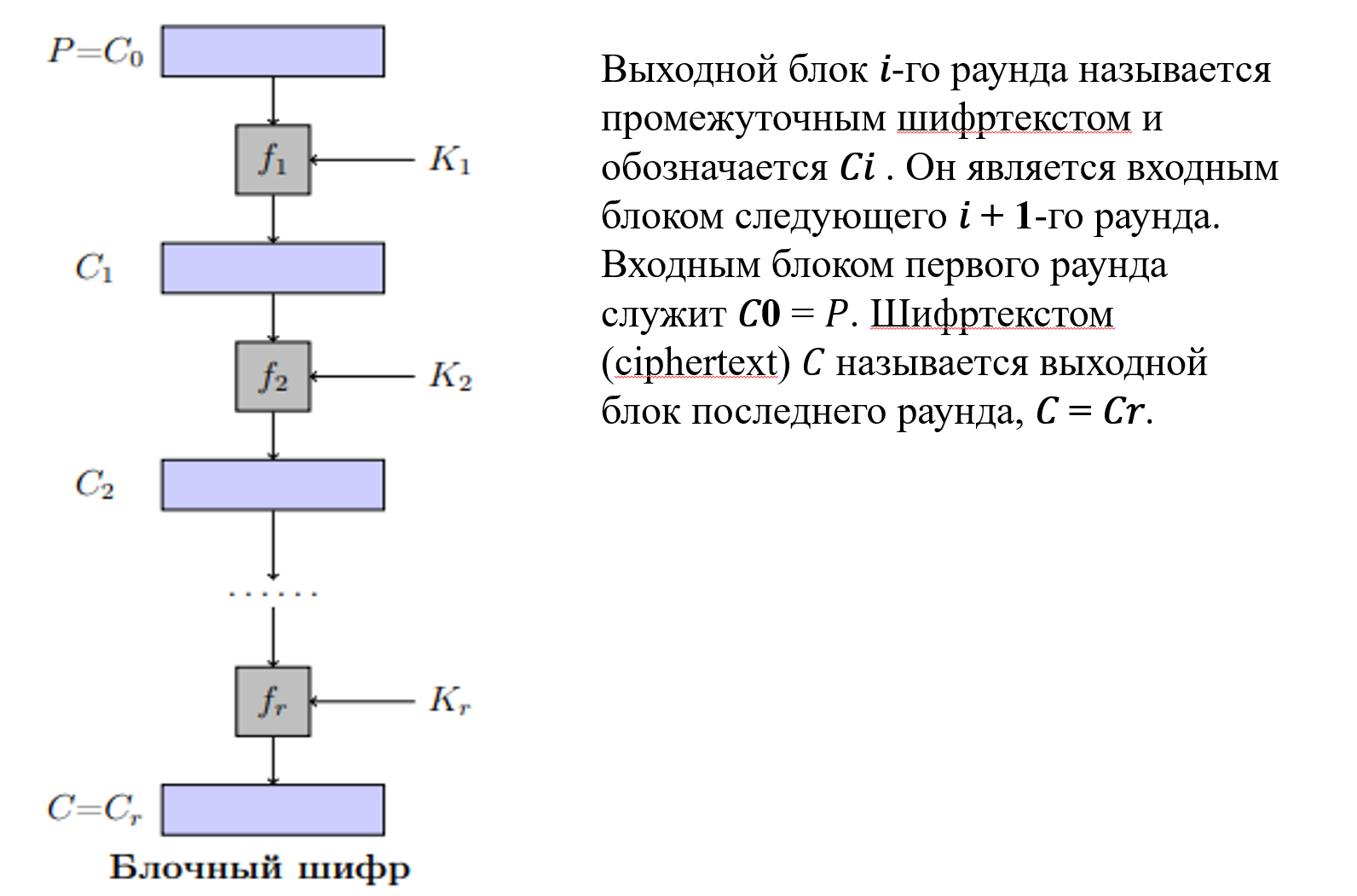


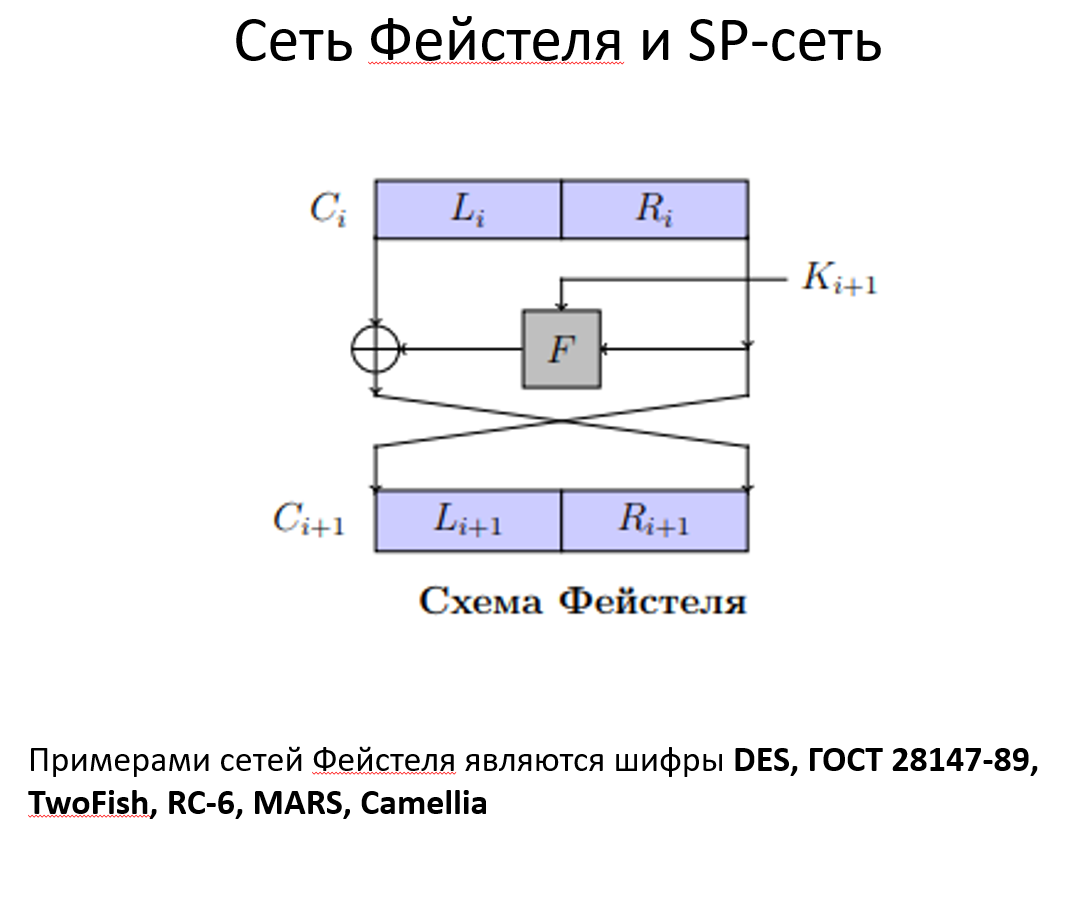
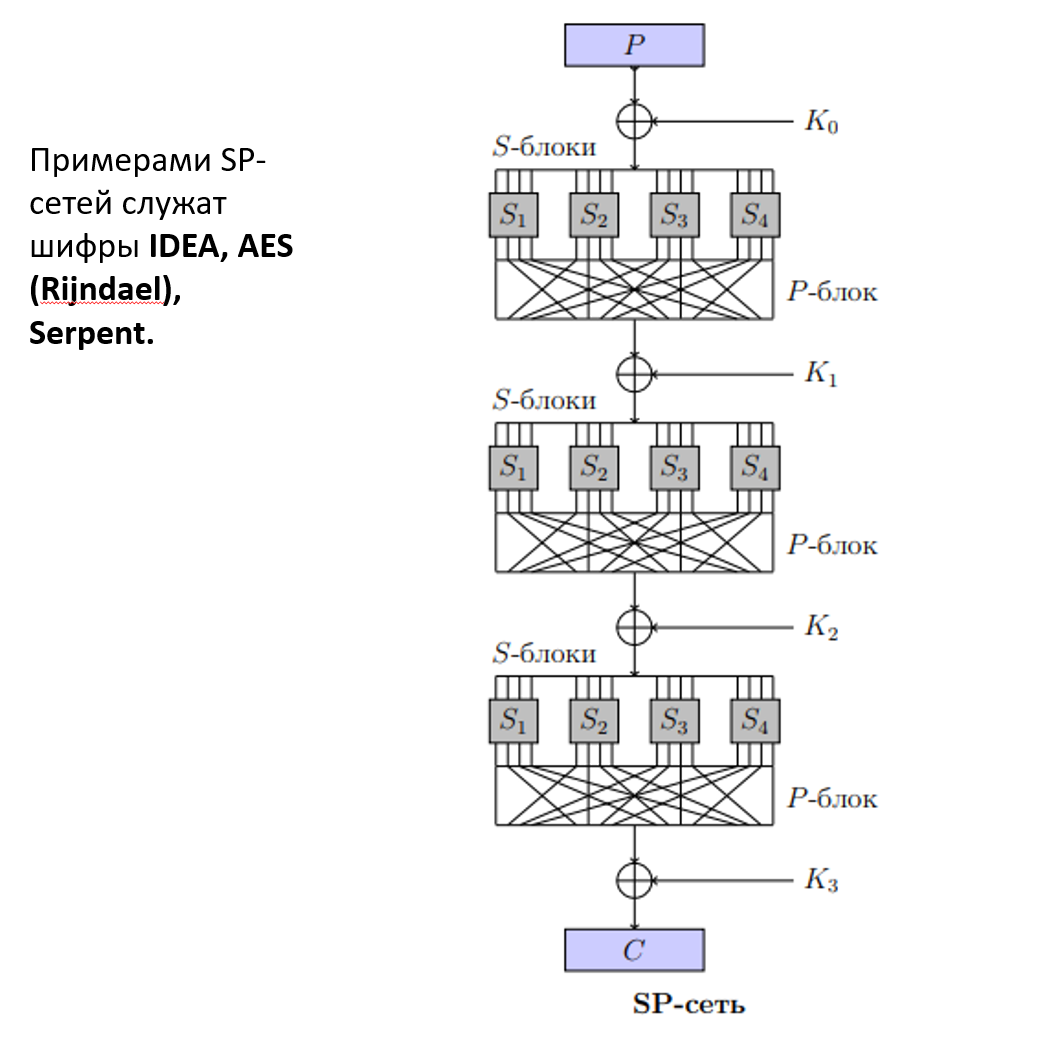
Большая их часть строится на сетях Фейстеля или SP сетях. В зависимости от того, какой алгоритм, меняется в основном функция Фейстеля.







Гаммирование - XOR сообщения, переведённого в двоичный вид с гаммой, т.е. случайным набором 0 и 1 полученным со стандартным распределением и имеющим одинаковое количество 0 и 1 (абсолютно криптостойкий шифр).

DES стандарт в США для важной но не секретной информации с 1980 по 1998
в 70х АНБ объявили конкурс который выиграли IBM с шифром Lucifer, который стал основой DES
АНБ поменяли размер ключа с 128 до 56 бит, поменяли s блоки (по одной версии для бэкдоров, по другой - для безопасности).
Шифрует блоки длиной 64 бита. Длина ключа - 56 бит. Число раундов - 16.
Будем считать что в каждом блоке биты нумеруются слева направо с первого бита. Ключ представляется блоком длины 64 бита. каждый восьмой бит - зависимый. Он равен сумма по модулю 2 предыдущих 7 битов + 1. Такие биты - проверки на чётность. На этапе подготовки из этого 64 битного ключа формируется 16 подключей длины 48 (ПО ТАБЛИЧКЕ). Сначала по ключу строятся блоки и (В презе), каждый из 28 битов. В них не входят зависимые биты ключа . Далее, начиная с блоков и начинаем строить блоки и (в которые входят числа от 1 до 16). Они получаются из и по таблице (в презе) смотрим куда надо циклически сдвинуть (на какое кол-во бит влево). Потом подключ (48 битов) формируется для раунда из (56 битов) по табличке (первые 28 - из , дальше из ).
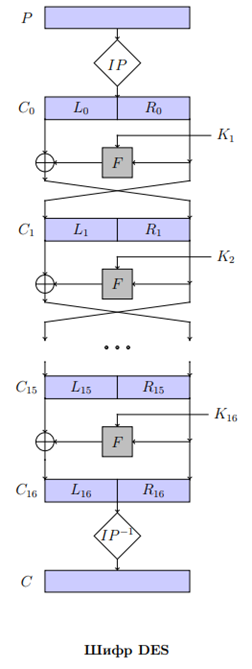
Схема шифрования в презе. Блок plaintext подаётся на вход как начальная перестановка (IP) и перестанавливается (по таблице). полученный блок разбивается на левую и правую половины . По сети фейстеля вычисляется всё от 1 до 15 раунда. На 16 раунде работает подругому. В нём не меняются местами. После всего этого идет обратная перестановка (по ещё одной таблице). Шифрование и дешифрование совпадают. Раундовые ключи надо применять в обратном порядке для дешифрования. Проходит NIS тесты.
На каждом раунде применяется одна и та же раундовая функция от . Результат XOR с
(32 бита) и результат функции тоже 32 битный вектор (потому что надо XOR с левой частью). Из 32 битного блока делаем 48 битный через расширяющую подстановку E (табличка в презе) становится 48 битным. Некоторые биты в рамках этого процесса дублируются. Полученное E XOR с , полученный 48 битный блок разбиваем на 8 блоков длины 6 бит и они идут на вход S блокам, после которых выходит по 4 бита. Полученный 32 битный блок прогоняем через P-блок (очередная перестановка по табличке). ТАБЛИЧКИ УЧИТЬ НЕ НАДО. S-блоки тоже приводятся через таблицу. На вход идёт вектор 6 бит. определяет строку в таблице, а - столбец. находим пересечение и переводим число на которое попали в двоичку.
пример:
Допустим 100101 и это первый блок. Получаем строку 11 и стоблец 0010 - это число 8, т.е. 1000.
DES имеет разные режимы работы.
- функция, где P - текст, K - ключ. Первый режим - электронная кодовая книга (Electronic code block, ECB). Тут блоки имеют размер 64. Преимущество - простота реализации, недостаток - не создаётся лавинный эффект, небезопасно, можно применять атаку со словарём.
Второй режим сцепление блоков шифротекста (CBC, Cipher block chaining). Тут . Каждая следующая часть зависит от предыдущей.
Третий - обратная связь по шифротексту (CFB, Cipher feedback block(?)). где - начальный вектор. Напоминает поточное шифрование.
Четвёрный - обратная связь по выходу (OFB, Output feedback block(?)). Открытый текста гаммируется (абсолютно криптостойкий шифр). , где , - начальный вектор. Отличие от CFB: гамма не зависит от последовательности открытых текстов. Требуется отдельный анализ гаммы для взлома.
DES получил распространение как в правительственных так и в коммерческих задачах. Из-за малой длины ключа утратил статус стандарта. Перед утратой статуса, лаборатория RSA дешифровала DES менее чем за 3 дня с помощью Brute force атаки на компьютере DES Cracker. Также вышло несколько научных статей на тему криптоанализа, в которых говорится что можно применить диференциальную и линейную атаку для взлома DES. Сейчас вместо него применяется 3DES с увеличенной длиной ключа в 168 битов. 3DES долго работает, но является безопасным и применяется в VISA, для шифрования PGP.
На каждый раунд нужен раундовый ключ размерностью 32 бита. Исходный имеет размер 256, разбиваем на 8 блоков по 32 бита. На каждый раунд используется раундовые ключи соответсвующие , а на последнем круге - порядок обратный, т.е.
Блок текста разбивается на левую и правую половины и проходит с 1 до 31 раунда как в DES по схеме Фейстеля. Раунд 32 вычисляется по другому:
На вход F получает . Оба 32 бита. Входные складываем по модулю 32 (переводим числа в 10чную систему, суммируем по модулю (у нас 32), снова переводим в двоичную). Эта сумма делится на 8 групп по 4 бита и подаются соответствующему S-блоку. Из них выходят тоже по 4, получаем 32 бита. Она сдвигается циклически побитово на 11 бит влево. Это будет выходом из функции.
Особенность ГОСТа в том, что компетентные органы могут использовать разные наборы блоков, что делает шифрование одних организаций сильнее, а других слабее.
Алгоритм не особо быстрый. С точки зрения аппаратной реализации его конструкция очень удачная, выдерживает брутфорсы. В мире считается не достаточно хорошим для того чтобы быть стандартом, в 2010 его попробовали выдвинуть на конкурс ISO, но он проиграл AES, а позже был дважды атакован. Атаки понизили заявленную криптостойкость с до .
В 1997 году объявлен конкурс на новый стандарт блочного шифрования. Рассматривалось 15 заявок, вышло в финал 5 (слайд 17), все из которых признаются криптографически стойкими, но победителем стал шифр Rijndael. после небольшой доработки этот шифр был принят новым стандартом в 2002 и получил официальное название Advanced Encryption Standart (AES). Это классическая SP-сеть (подстановочная-перестановочная). Длина шифруемого блока - 128 бит, длина ключа 128, 192 или 256 бит. Число раундов - 10, 12, 14 (в зависимости от длины ключа). Будем рассматривать версию на 128 битный ключ с 10 раундами. Каждый промежуточный шифротекст называется состоянием (State) и показывают матрицей 4х4 (18 слайд). Для 10 раундового шифрования требуется 11 подключей длины 128. Каждая ячейка в таблице a состоит из 8 битов. В самом начале блок открытого текста XOR с нулевым раундовым подключом () и результирующий блок () подаётся на вход первого раунда.
Заключается в многократном применении раундового преобразования к блоку , каждый выход является входом для следующего. Каждый i раунд состоит из 4 простых преобразований (на презе 19 слайд). Это происходит с 1 раунда по 9. В 10 раунде не применяется MixColumns().
Каждый байт состояния заменяется на другой байт с помощью S-блока
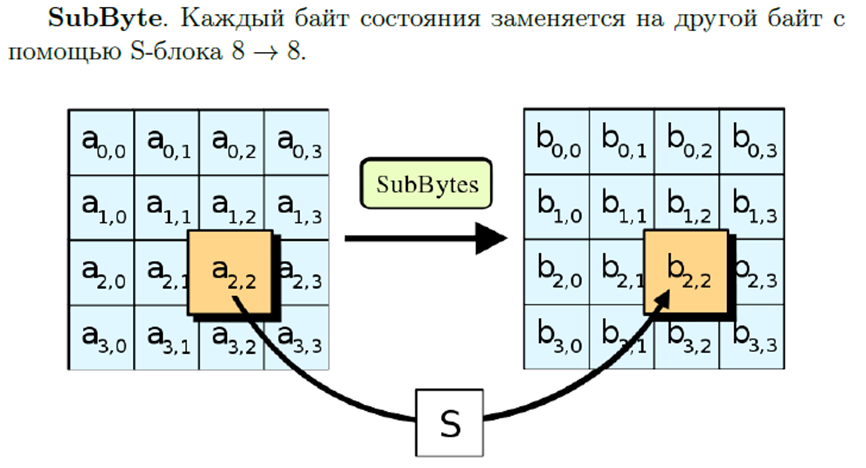
S-блок заранее фиксирован и известен. Чтобы по нему определить выходные данные надо взять набор из 8 битов на вход, представить его в 16-ричном виде и найти значения по таблице.

Полученное hex переводим обратно в двоичку
Циклический сдвиг ячеек в матрице a
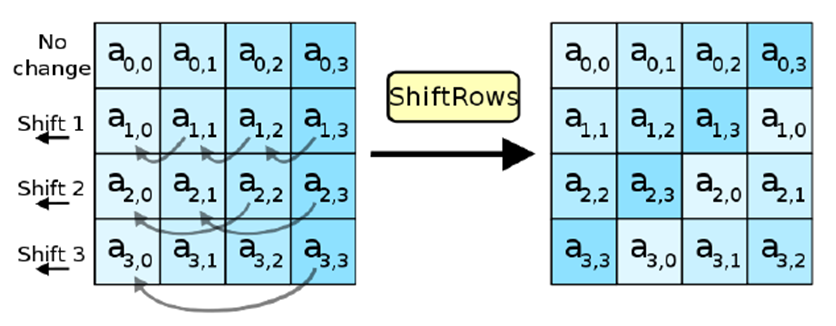
Первая строка не сдвигается, вторая сдвигается на 1, третья на 2, четвёртая на 3. (т.е. сдвигаем строку влево на номер_строки-1)
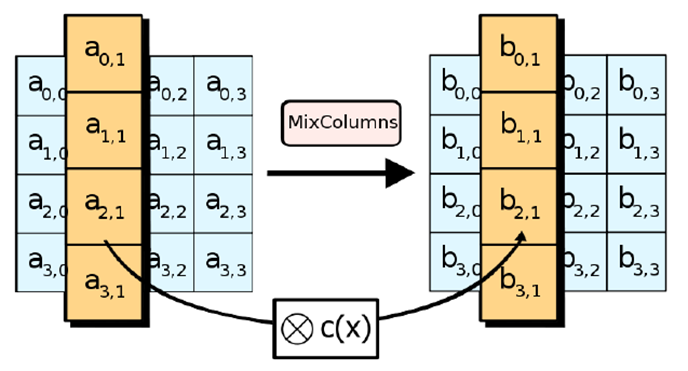
Каждый j столбец меняется на новый столбец. b получаем так:
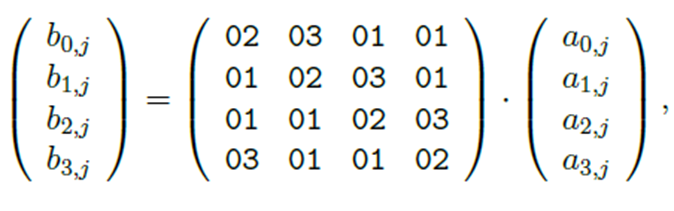
Матрица в hex умножается на заменяемый столбец. умножения и сложения рассматриваются как операции в поле (берём по mod )
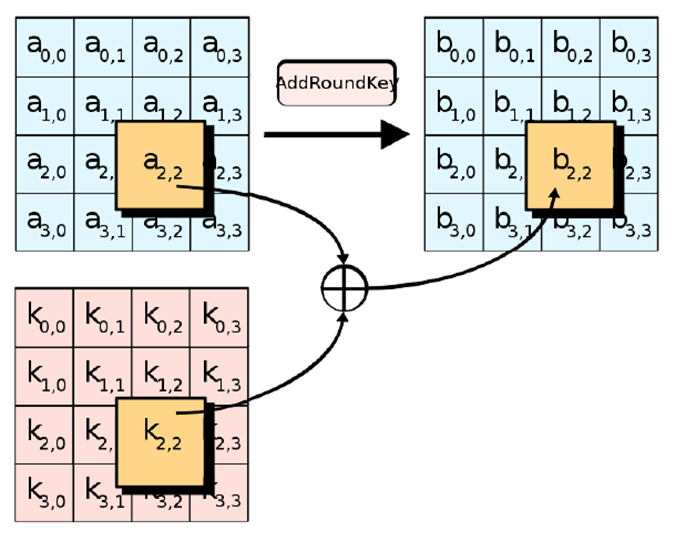
Проводим xor соответствующих элементов a и k (матрица раундового ключа).
Для расшифровки надо применять раундовые ключи в обратном порядке. MixColumns тоже обратно проводится, для SybBytes есть обратная таблица.
Для 10 раундового AES надо 11 (нулевой ксорим с плейнтекстом) ключей длины 128 бит.
Общая длина всех ключей 1408 бит. Из ключа k мы построим расширенный ключ размерности 1408 битов. Для этого ключ k разбивается на 4 блока
Каждый блок имеет длину 32 бита разбиваем равномерно. Обычно это называется словом word. Начиная с 4 элемента w мы находим по правилу:

Это можно делить на блоки по 128 для раундового шифрования.
имеют длину 32 бита где - константы, которые задаются алгоритмом, как и таблица SubBytes.
Используются с ЭлектронноЦифровойПодписью для проверки целостности данных. Для тех же целей можно применять контрольные суммы, биты чётности.
Функция Хэширования - детерминированная функция, получающая на вход биты произвольной длины, выдающая список битов фиксированной длины. Называются по всякому, но в основном Хэш.
, где m - сообщение (Прообраз функции, исходная строка). Когда хэши проверяются или оцениваются, применяются
Стойкость к поиску первого прообраза. Нет эффективного полиномиального алгоритма который дал бы вычислить m по хэшу, а значит хэш - односторонняя функция.
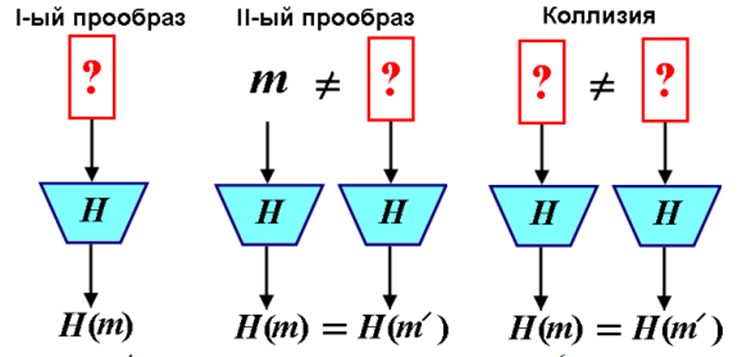
Стойкость к поиску второго прообраза (коллизиям первого рода). Вычислительно невозможно зная сообщение m и его свёртку (хэш ) найти такое другое сообщение когда
Стойкость к коллизиям второго рода. Коллизией для хэш функции называется такая пара значений m и m', что . Допустим длина прообраза 6, а свёртки - 4 бита. Тогда число различных свёрток будет , а число образов . Нет эффективного полиномиального алгоритма для поиска коллизий.
Замечания:
Обратимая функция неустойчива к восстановлению второго прообраза и коллизиям.
Функция нестойкая к восстановлению второго прообраза не стойкая и к коллизиям, обратное не верно.
Функция, устойчивая к коллизиям, устойчива к нахождению второго прообраза.
Устойчивая к коллизиям хэш функция не обязательно является одностононней.
Хэш функция обладает лавинным эффектом, даже при малейшем изменении информации, хэш меняется полностью
Когда говорят про хэш функции упоминается схема Меркеля-Дамгарта
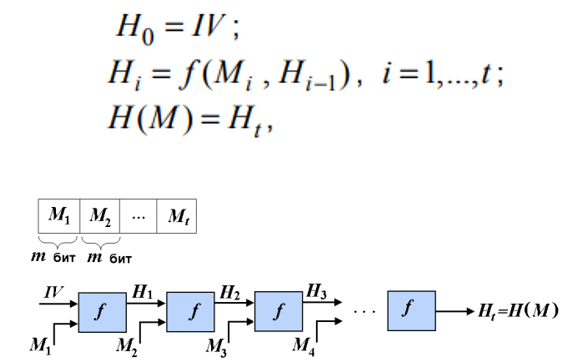
Функция сжатия- функция 2 переменных где - битовые строки длины m, а y - битовая строка длины n
В конец хэшируемого сообщения M приписывается длина сообщения и дополнение, но так, чтобы длина сообщения стала кратна его длине (m - длина строки, которое может обработать функция сжатия). Пусть сообщение разбито на t m-битовых блоков ,а свёртки, получаемые в ходе итерации обозначим как . IV - константа. Доказано что если функция сжатия устойчива к коллизиям, то и вся хэш функция устойчива к коллизиям.
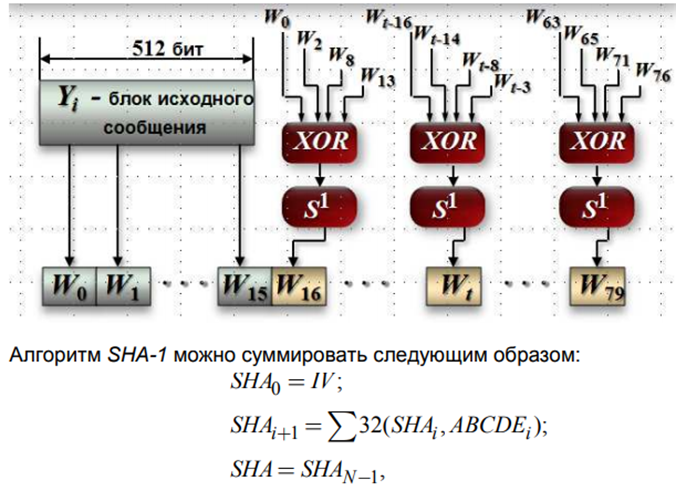
Выдаёт 160 бит хэша, длина обрабатываемого блока- 512 бит, Число шагов алгоритма - 80 (4 раунда по 20 шагов), максимальная длина данных - $2^
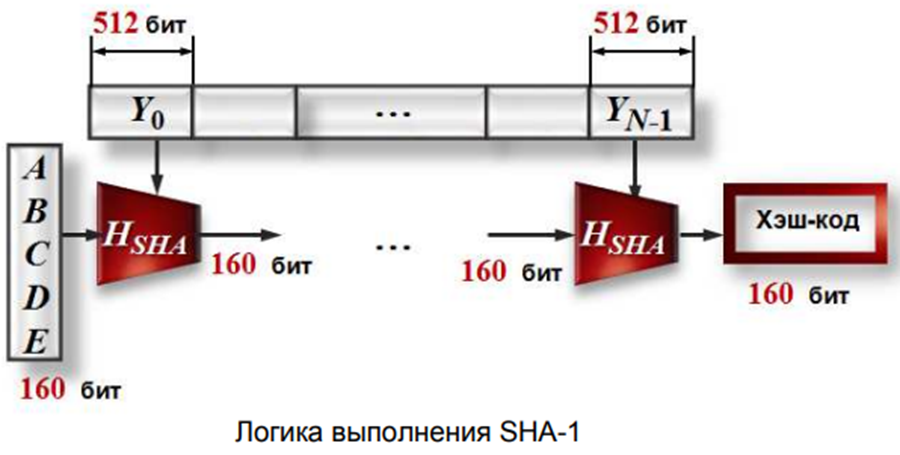
Первый шаг. Исходное m битовое сообщение расширяется до длины, кратной 512 следующим образом:
двоичная запись числа m, а s - наименьшее число при котором . s-1 - количество нулей. Допустим подаётся 2590 битов. Сколько будет содержать дополнение сообщения
Это значит что будет 1 единица и 63 нуля. 94 - ответ. Надо добавлять даже есть m кратно 512
Используется 160-битный буфер для хранения промежуточных и окончательных результатов хэш функции
Буфер может быть представлен как 5 32-битных регистров A,B,C,D,E, которые инициализируются следующими цифрами

Основой алгоритма является модуль который состоит из 80 циклических обработок. Все 80 циклических обработок имеют одинаковую структуру. Каждый цикл получает на вход текущий 512 битный обрабатываемый блок . и 160-битное значение буфера A,B,C,D,E и каждый раз меняет содержимое этого буфера
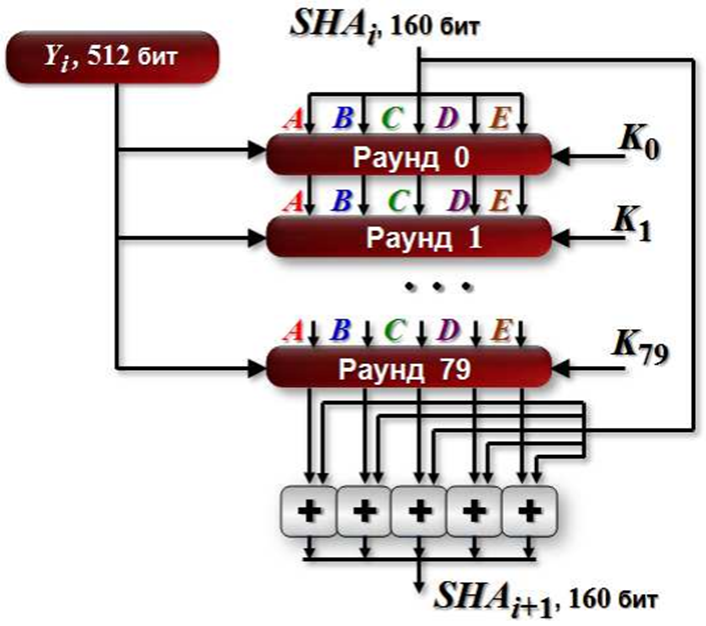
K может принимать только 4 разных значения. Эти 4 значения:

Выходом будет 160 битный дайджест сообщения.

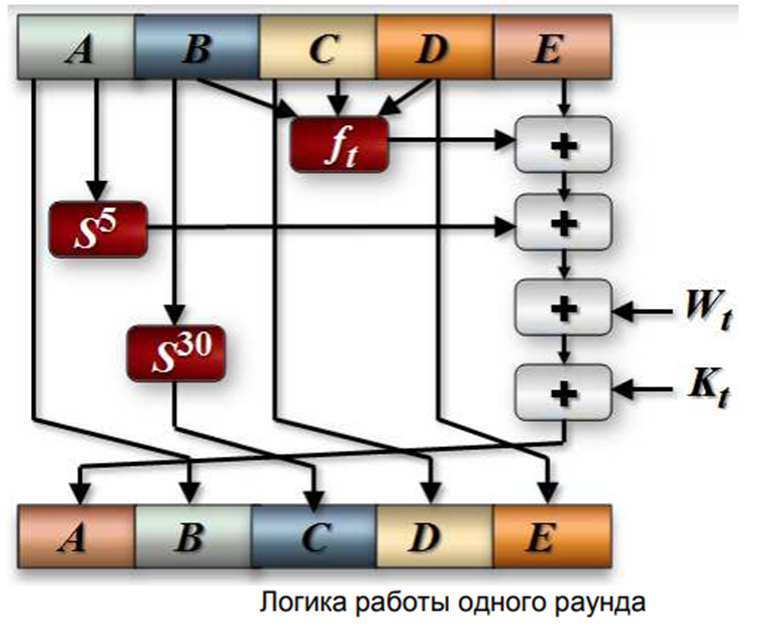
Константы :
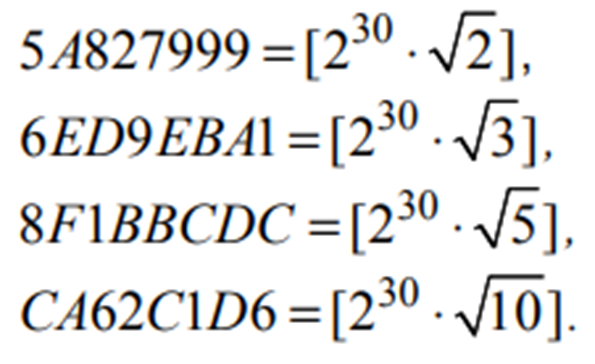
объяснение:

:
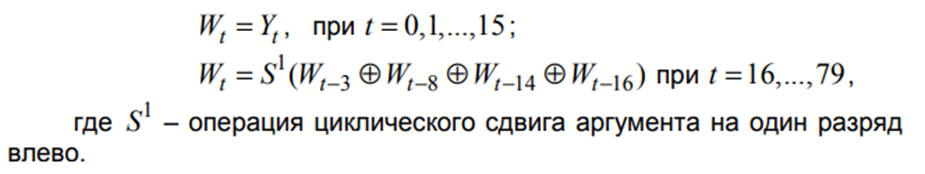
Электронная Цифровая Подпись позволяет подтвердить подлинность электронного документа (будь то реальный человек или, например, аккаунт в криптовалютной системе). Подпись связывается как с автором, так и с самим документом криптографическими методами и не может быть подделана путем обычного копирования.
ЭЦП является требованием электронного документа, полученного в результате криптографического преобразования информации с закрытым ключом подписи, и позволяет проверить отсутствие искажения информации в электронном документе с момента формирования подписи (целостность), подпись принадлежит владельцу сертификата ключа подписи (авторство), и в случае успешной проверки подтверждает факт подписания электронного документа (неотказуемость).
Чтобы реализовать электронно-цифровую подпись можно использовать следующий метод:
С помощью алгоритма Диффи-Хеллмана генерируем открытые и закрытые ключи между пользователями. То же самое делаем для RSA.
Обычные сообщения, не требующие ЭЦП шифруются только с помощью RC4 ключом, полученным на 1 шаге.
Для важных сообщений применяем хэширование. Перед отправкой зашифрованного сообщения мы отправляем его хэш (Хэширование с помощью MD5), зашифрованный RSA. После, отправляем само сообщение.
Получающий сам хэширует полученное сообщение и сравнивает с ранее полученным хешем. Если совпали - значит изменений в файле не произошло, целостность сохранена!
X.509 — стандарт ITU-T для инфраструктуры открытого ключа (англ. Public key infrastructure, PKI) и инфраструктуры управления привилегиями (англ. Privilege Management Infrastructure).
X.509 определяет стандартные форматы данных и процедуры распределения открытых ключей с помощью соответствующих сертификатов с цифровыми подписями. Эти сертификаты предоставляются удостоверяющими центрами (англ. Certificate Authority). Кроме того, X.509 определяет формат списка аннулированных сертификатов, формат сертификатов атрибутов и алгоритм проверки подписи путём построения пути сертификации. X.509 предполагает наличие иерархической системы удостоверяющих центров для выдачи сертификатов.
Например сертификат МинКомСвязи содержит: Дату регистрации, ФИО, адрес, ИНН
SSL (Secure Sockets Layer) и TLS (Transport Layer Security) - это криптографические протоколы, предназначенные для обеспечения безопасной связи по сети. TLS фактически является преемником SSL и считается более безопасным.
Описание механизма защиты TLS (с учетом упомянутых ГОСТов):
Аутентификация клиента и сервера: Процесс подтверждения, что сервер и (опционально) клиент являются теми, за кого себя выдают. Это обычно достигается с помощью сертификатов X.509. Сертификат содержит открытый ключ сервера и информацию о нем, подписанную доверенным центром сертификации (CA). Клиент проверяет подпись CA, чтобы убедиться в подлинности сертификата. Использование ГОСТов в этом контексте скорее всего подразумевает использование российских криптографических стандартов для генерации ключей и формирования подписей в сертификатах.
Шифрование информации: ГОСТ 28147-89 - это российский стандарт симметричного шифрования. После согласования сеансового ключа (описывается ниже) данные шифруются с помощью этого алгоритма, обеспечивая конфиденциальность.
Контроль целостности информации: ГОСТ Р 34.11-94 (аналог MD5) - это российский стандарт хэширования. Для обеспечения целостности данных вычисляется хэш-значение передаваемого сообщения. Получатель также вычисляет хэш и сравнивает его с полученным значением. Любое изменение данных приведет к различному хэшу, что позволит обнаружить подмену или повреждение информации.
Обмен ключами по алгоритму Диффи-Хеллмана: Этот алгоритм позволяет двум сторонам безопасно согласовать общий секретный ключ по незащищенному каналу связи. Этот ключ затем используется для симметричного шифрования данных (в данном случае, ГОСТ 28147-89).
Протокол рукопожатия:
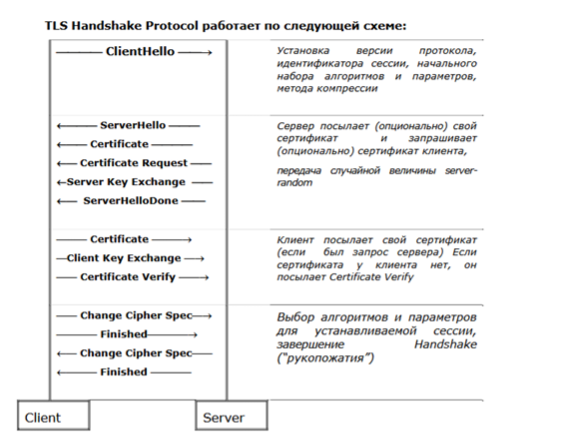
Стандартный процесс рукопожатия TLS в общих чертах выглядит так:
Client Hello: Клиент отправляет серверу информацию о поддерживаемых им версиях TLS, шифрах и алгоритмах сжатия.
Server Hello: Сервер выбирает подходящие параметры из предложенных клиентом и отправляет свой сертификат (включая открытый ключ).
Key Exchange: Производится обмен ключами по алгоритму Диффи-Хеллмана, в результате которого обе стороны получают общий секретный ключ.
Client Key Exchange: Клиент отправляет серверу свою часть данных для генерации общего ключа.
Server Key Exchange: Сервер отправляет клиенту свою часть данных для генерации общего ключа.
Change Cipher Spec: Клиент и сервер уведомляют друг друга о переходе к зашифрованной связи.
Finished: Клиент и сервер подтверждают успешное завершение рукопожатия и начинают обмен зашифрованными данными.
Отличия SSL от TLS:
SSL является устаревшим и имеет известные уязвимости. TLS - это более современный и безопасный протокол. Основные отличия включают:
Улучшенное рукопожатие: TLS имеет более надежный механизм рукопожатия, что снижает риск определенных атак.
Улучшенное управление ключами: TLS предлагает более гибкие и безопасные способы управления ключами сеанса.
Поддержка различных шифров: TLS поддерживает более широкий спектр криптографических алгоритмов, позволяя использовать более сильные методы шифрования.
Улучшенная проверка целостности: TLS использует более надежные механизмы проверки целостности данных, такие как HMAC.
Классический протокол на котором строятся онлайн казики и прочие штуки.
Алиса и Боб загадывают пойти куда либо. Если Боб угадывает подбрасывание монеты, идут куда хочет он, если нет - куда хочет Алиса. Для этого выбирается большое чётное и нечётное число, чётное назовём орлом, нечётное - решкой. Алиса подбросила - получила решку, нечётное шифруется своим открытым ключом и отправляет Бобу. Допустим Боб не угадал, сказав что это орёл. Алиса отправляет Бобу ключ для расшифровки. Боб расшифровал, убеждается что идёт куда хочет Алиса.
Есть Алиса и Боб. Есть пещера Али Бабы. В ней есть дверь. Алиса говорит что она знает ключ от этой двери. Боб не верит. Алиса спускается в пещеру и выходит с другой стороны. Боб не убеждён даже после перепроверки закрытости двери. Производится повторный проход для уверенности. Каждый проход через дверь удваивает шанс того, что Алиса реально знает ключ, при том что она его не показывает. Количество проходов зависит от системы. Алгоритм работает только если нет уязвимостей.
На цифрах: кого то надо пускать в систему, но мы не должны знать ключ. Мы отправляем данные и по ответам можем понять что их можно пускать.
Алиса говорит что умеет разгадывать Кубик Рубика. Боб не верит. Просит написать алгоритм. Алиса говорит что она не может показать алгоритм. Алиса передаёт Кубик-Рубика чтобы Боб запутал кубик и передал обратно Алисе. Алиса его решает и отдаёт обратно Бобу. Итеративно несколько раз прогоняем и убеждаемся что Алиса знает алгоритм. По сути то же самое, но вместо неизвестного ключа неизвестный алгоритм.
Идёт голосование по закону. Допустим сразу выходит что все за. А кто знает что депутаты голосуют? Как сделать с помощью криптографии так, чтобы голосование было анонимным, но при этом подделать голоса было невозможно.
Ответ из книги Музыкантски: для решения используется RSA и затемняющий множитель. Затемняющий множитель должен быть больше чем простые числа (голос за, против, воздержался). Тоже простое. При голосе ЗА мы берём случайный затемняющий множитель в каком то диапазоне. Он умножается на наше простое число (голос). шифруем открытым ключом сервера. Отправляем. Все собранные числа, которые делятся на 2 - за, которые делятся на 3 - против и т.д. Остальные - воздержался.
Надо реализовать честные Тендеры. Объявляются закупки компьютеров. Выигрывают те, кто предложил наименьшую стоимость. Мы не должны знать сколько участники предложили.
Ответ: Объявляется открытый ключ, им участники шифруют сумму, когда пора выбирать объявляется закрытый ключ и все могут посмотреть кто сколько предложил и выиграл торги.
Как обыграть Каспарова или Карпова или сыграть в ничью.
Надо дублировать ход одного другому. MITM атака.